About data processing
Stemformatics processes all data hosted from raw files, rather than hosting post-processed files. This is done to ensure we can apply uniform quality control metrics across all datasets and reject those which do not meet these requirements. Most of the published data come from online repositories such as GEO or ArrayExpress.
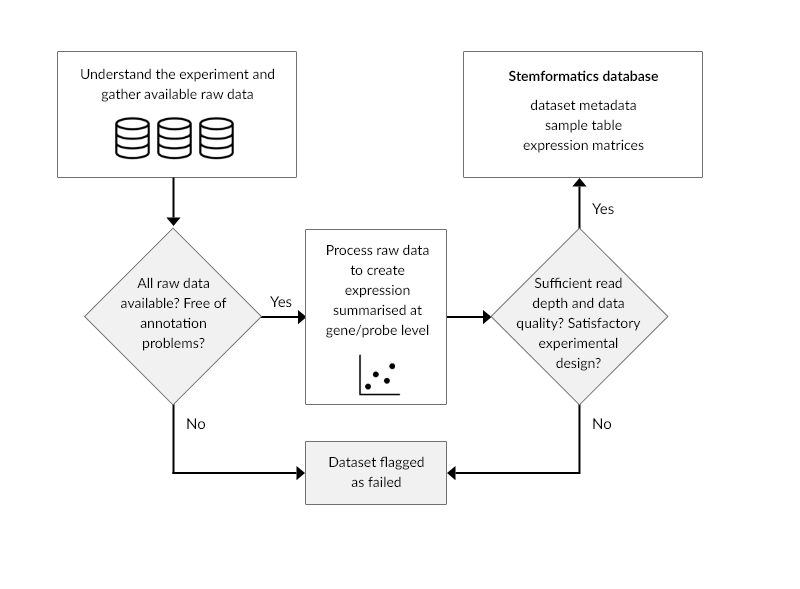
We have found over the years that about 30% of all datasets we process fail our quality control metrics. Common issues include poor experimental design (such as batch effect confounding biological classes of interest or insufficient sample class replication), or misannotation of samples, or missing parts of primary data.
About sample annotations
All Stemformatics datasets have been curated to ensure quality. One of the most challenging aspects of curation process involves annotating the samples, and we do a lot of this work manually applying domain specific knowledge. This allows us to highlight key similarities and differences in the context of the biological questions being asked.